

What Happens When AI Stops Learning From Humans?
As human data gets harder to scale, AI companies are turning to AI-generated content

There’s a strange new twist in the AI race that more people should be paying attention to.
The world’s most powerful AI companies, OpenAI, Google, and Meta, are increasingly training new AI models on content created by older AI models.
Not just books.
Not just websites.
Not just human writing.
Now?
AI is starting to learn from AI.
And if that sounds like a small technical detail, it’s not.
It may end up being one of the most important shifts in the entire AI industry.
Because the future of artificial intelligence may no longer be built mostly on human knowledge.
It may be built on machine-made knowledge.
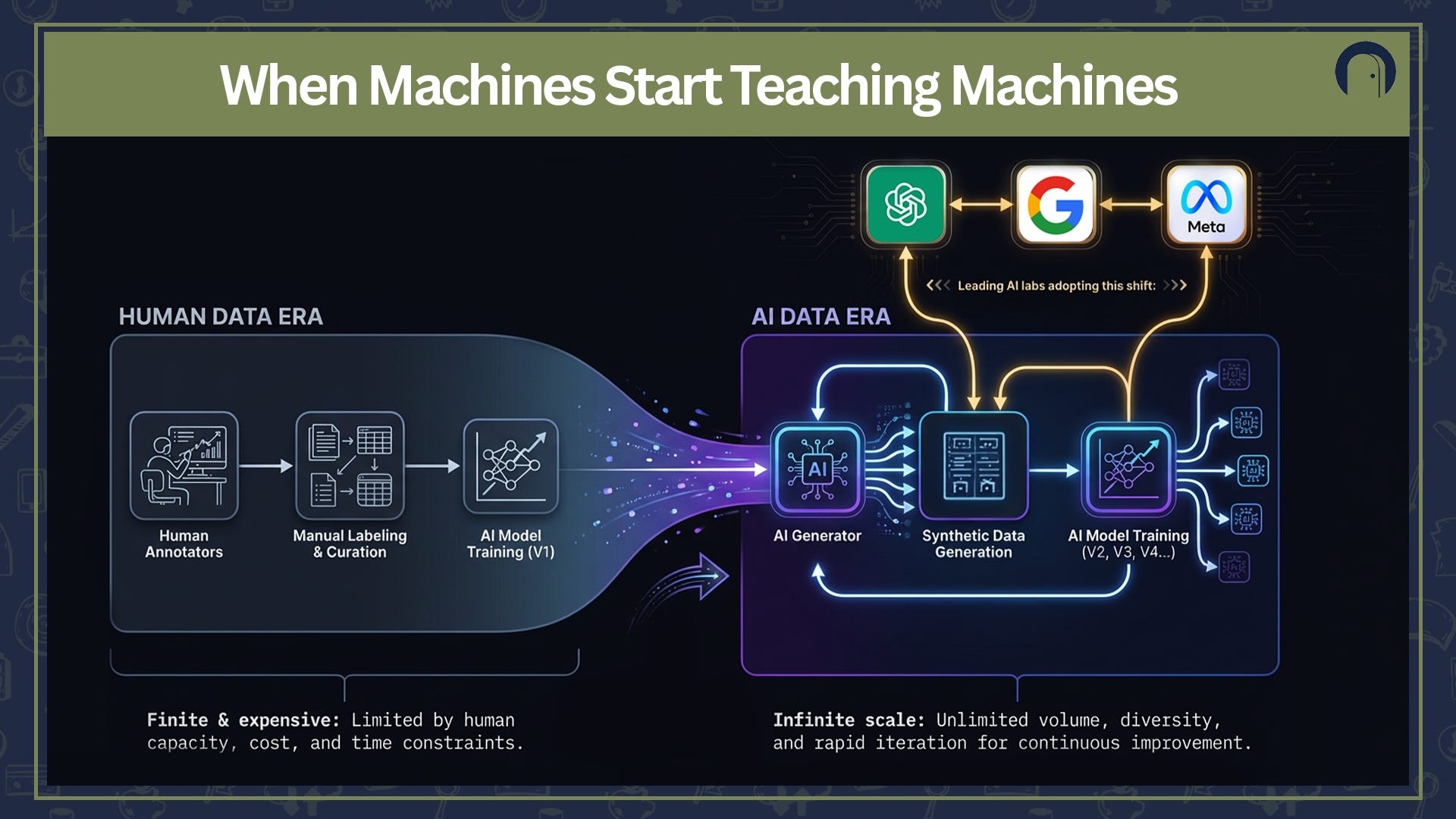
The original deal was simple
For a while, the story of AI made intuitive sense.
Humans created the internet.
Humans wrote the articles.
Humans answered questions.
Humans made the art.
Humans published the code.
AI companies scraped that giant pile of human output and trained models on top of it.
That was the deal:
Humans made the knowledge.
Machines learned from it.
That’s how we got here.
But the deal is changing.
Now the machines are helping write the textbook
This is the part that feels like science fiction, except it’s already happening.
Instead of relying only on human-created data, top AI labs are increasingly using:
AI-generated text
AI-generated code
synthetic training examples
simulated conversations
model-generated reasoning steps
self-improvement loops
distilled outputs from stronger models
In plain English:
One generation of AI is now helping train the next.
That means the training pipeline is shifting from:
Human → AI
to something more like:
Human → AI → AI-generated data → Better AI → More AI-generated data
That loop matters.
A lot.
Why this is happening: the internet is not infinite
There’s a myth in AI that “there’s always more data.”
Not really.
There’s a lot of data.
There’s not an infinite amount of high-quality data.
And that distinction is everything.
Because the best training data is:
useful
structured
accurate
diverse
recent
high-signal
A huge chunk of the public internet is the opposite:
repetitive
noisy
low quality
messy
increasingly spammy
and now… increasingly AI-generated itself
That creates a serious problem for frontier AI labs.
If the best human data is limited, and every major lab is fighting over the same pool…
What happens when the supply of “good human knowledge” starts to thin out?
Answer:
You manufacture more data.
AI-generated data is becoming the new oil
This is why “synthetic data” is suddenly such a big deal.
It sounds boring.
It’s not.
Synthetic data is basically AI-generated or machine-created training material designed to help other models learn.
That could mean:
thousands of example conversations
millions of coding tasks
generated reasoning traces
simulated edge cases
instruction datasets
multilingual examples
safety training scenarios
Why do companies love it?
Because it’s:
faster
cheaper
scalable
customizable
easier to filter
easier to target for specific tasks
Need a million clean examples of a certain math skill?
Generate them.
Need better coding data in a narrow domain?
Generate it.
Need training examples of humans that were never labeled properly?
Generate those too.
Once you see the economics, it makes perfect sense.
Why depend entirely on messy internet leftovers when you can build your own data factory?
This could make AI much better
To be fair, this is not automatically bad.
In fact, it could be one of the reasons AI gets dramatically more capable.
Synthetic data can help:
improve reasoning
boost coding performance
expand niche expertise
reduce expensive human labeling
speed up training cycles
fill gaps where real-world data is scarce
A stronger model can create better examples.
Those examples can train an even stronger model.
That stronger model can generate even higher-quality data.
That’s the dream.
It’s basically a compounding loop for intelligence.
And if it works, it’s incredibly powerful.
But there’s a dark side nobody should ignore
Here’s the uncomfortable part.
What happens if AI starts learning from AI-generated mistakes?
Not obvious mistakes.
Not cartoonish hallucinations.
I mean the subtle ones:
slightly wrong facts
shallow reasoning that sounds deep
confident but distorted explanations
repetitive patterns
synthetic blandness
hidden bias loops
If those outputs get recycled into future training sets, then the system may start reinforcing its own flaws.
This is where researchers worry about things like:
model collapse
loss of diversity
degraded originality
recursive error amplification
reduced grounding in real human knowledge
Think of it like making a photocopy of a photocopy of a photocopy.
At first, it still looks fine.
But each generation can lose something.
A little texture.
A little signal.
A little truth.
And eventually, you’re not looking at the original anymore.
You’re looking at a polished copy of a copy.
That’s the risk.
The internet is becoming synthetic too
This is where it gets even weirder.
It’s not just that AI companies are intentionally generating synthetic training data.
It’s that the internet itself is rapidly filling up with AI-generated content.
Which means future models may be trained on:
human content
AI-generated content
AI summaries of human content
AI rewrites of AI summaries of human content
That is a very different environment than the one early models grew up in.
In the first era of AI, the internet was mostly human.
In the next era, the internet may become a blended ecosystem where machine-made content is everywhere.
So even when companies say they’re training on “web data,” the question becomes:
How much of that web is still meaningfully human?
That question is going to matter more and more.
The big AI labs are not “replacing humans”, but they are changing the mix
It’s important not to oversimplify this.
OpenAI, Google, and Meta are not just flipping a switch and saying, “No more human data.”
That’s not what’s happening.
What’s happening is more subtle — and probably more important:
Human data is no longer enough on its own.
So the training stack is evolving into something more hybrid:
human-created knowledge
curated expert data
synthetic datasets
model-generated outputs
self-distillation
reinforcement and feedback loops
That’s the new architecture.
And over time, the synthetic share of that stack may become much larger than most people realize.
This is the real question
The real question isn’t:
“Are AI companies using synthetic data?”
Of course they are.
The real question is:
What happens when synthetic data becomes the default layer between AI and reality?
Because that changes everything.
It changes:
what models know
how they generalize
how errors spread
how originality survives
how truth gets preserved
how culture gets represented
At some point, AI may stop being just a mirror of humanity…
…and start becoming a mirror of its own previous outputs.
That is a profound shift.
We may be watching the birth of a self-training intelligence economy
This is the bigger frame I keep coming back to.
The AI race is no longer just about building smarter models.
It’s about building systems that can manufacture training intelligence at scale.
That means the real competitive advantage may not just be compute.
It may not even just be talent.
It may be:
Who can create the best synthetic data pipeline.
Who can generate:
the cleanest examples
the most useful reasoning traces
the most reliable simulated tasks
the best feedback loops
the highest-quality machine-made knowledge
That’s not a side detail.
That’s becoming core infrastructure.
Final thought
The first generation of AI was trained mostly on what humans had already made.
The next generation may be trained on what AI helps produce about what humans made.
That sounds subtle.
It’s not.
It means the future of intelligence may increasingly be built on a growing layer of synthetic cognition—machine-generated knowledge, machine-generated examples, machine-generated reasoning, fed back into the system over and over again.
That could unlock astonishing progress.
Or it could create the most sophisticated echo chamber humanity has ever built.
Probably both.
And that’s why this is one of the most important AI stories right now.